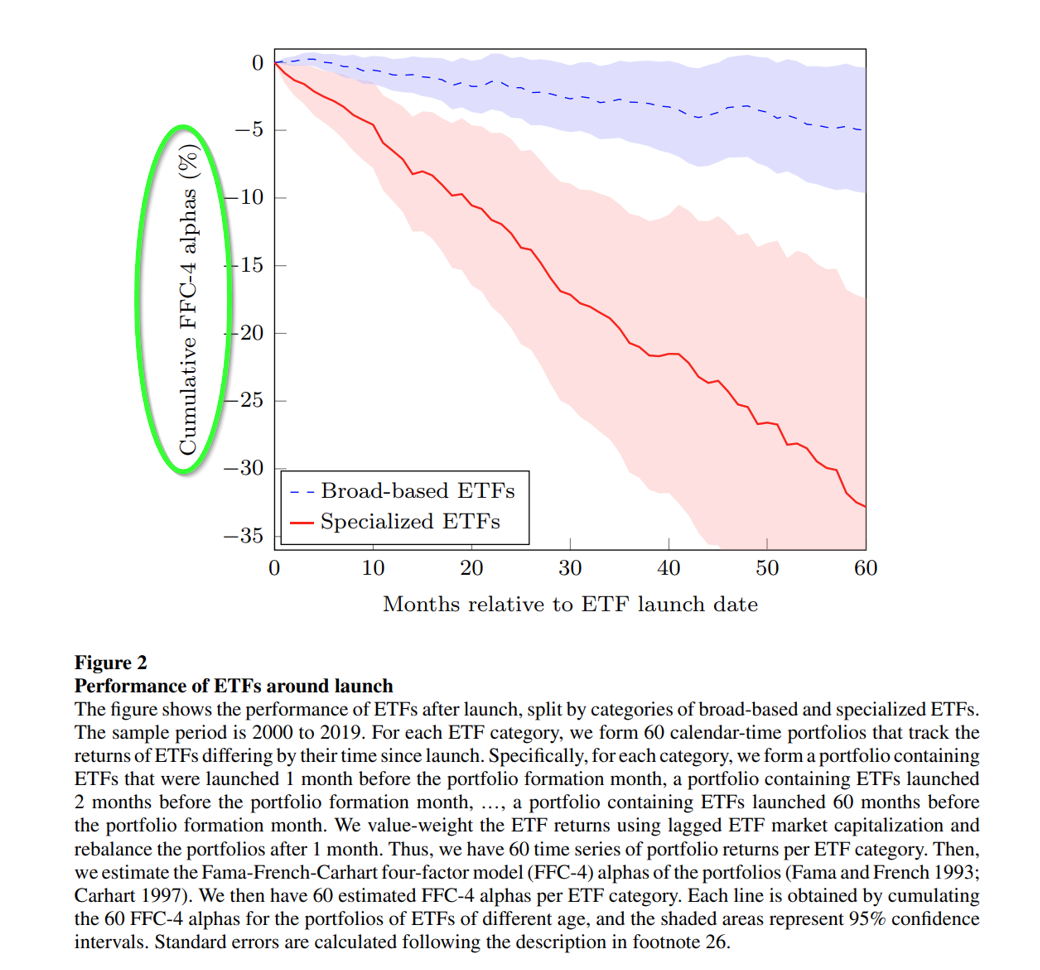
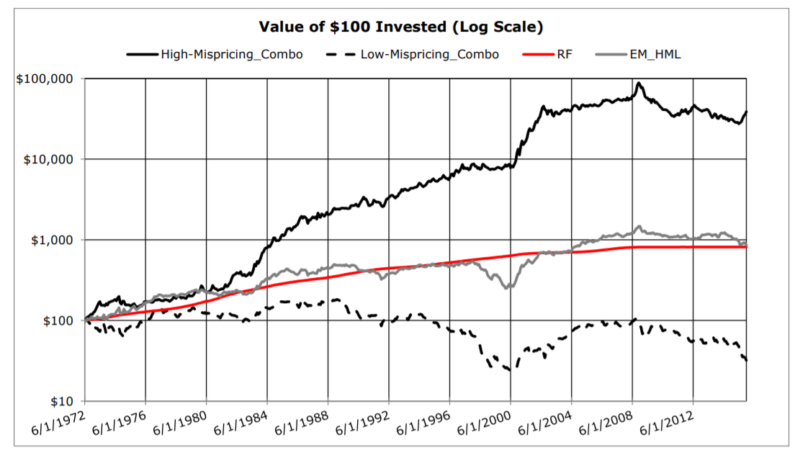
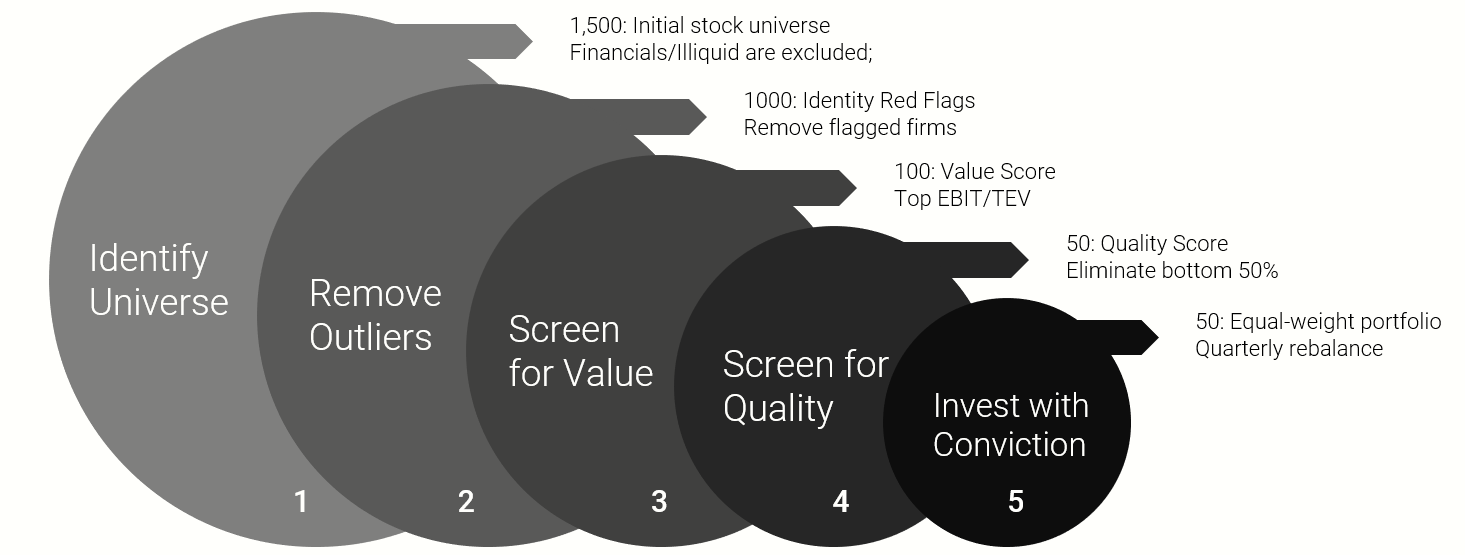
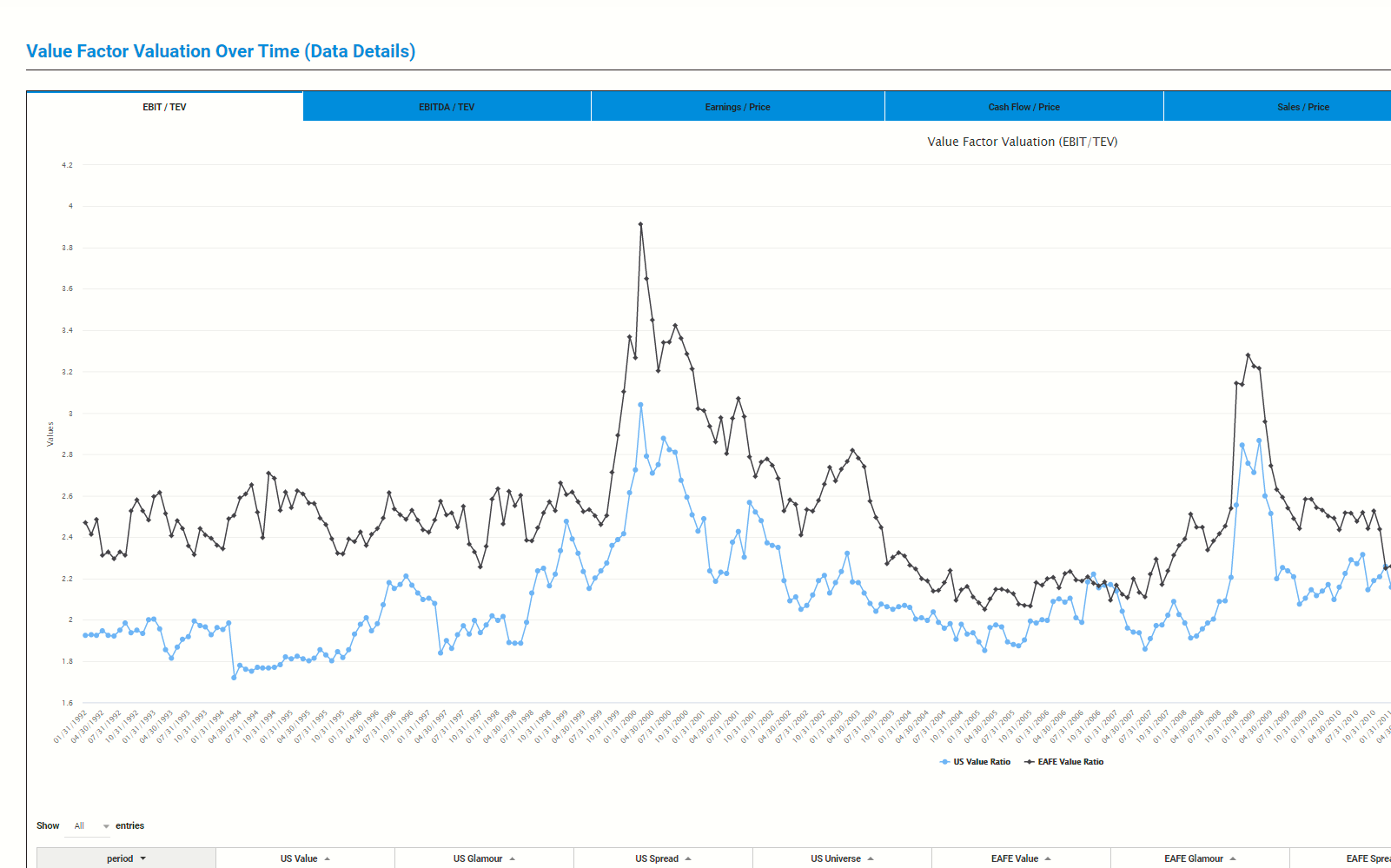
About Alpha Architect
WE ARE A NATIONALLY RECOGNIZED
ASSET MANAGEMENT INNOVATOR






About Alpha Architect

CEO & Co-CIO
After serving as a Captain in the United States Marine Corps, Dr. Gray earned an MBA and a PhD in finance from the University of Chicago where he studied under Nobel Prize Winner Eugene Fama. Next, Wes took an academic job in his wife’s hometown of Philadelphia and worked as a finance professor at Drexel University. Dr. Gray’s interest in bridging the research gap between academia and industry led him to found Alpha Architect, an asset management firm dedicated to an impact mission of empowering investors through education. He is a contributor to multiple industry publications and regularly speaks to professional investor groups across the country. Wes has published multiple academic papers and four books, including Embedded (Naval Institute Press, 2009), Quantitative Value (Wiley, 2012), DIY Financial Advisor (Wiley, 2015), and Quantitative Momentum (Wiley, 2016). Dr. Gray currently resides in Palmas Del Mar Puerto Rico with his wife and three children.

CFO & Co-CIO
Dr. Vogel conducts research in empirical asset pricing and behavioral finance. Dr. Vogel is a co-author of DIY FINANCIAL ADVISOR: A Simple Solution to Build and Protect Your Wealth and QUANTITATIVE MOMENTUM: A Practitioner’s Guide to Building a Momentum-Based Stock Selection System. His academic background includes experience as an instructor and research assistant at Drexel University in both the Finance and Mathematics departments, as well as a Finance instructor at Villanova University. He has a Ph.D. in Finance and an MS in Mathematics from Drexel University. Dr. Vogel graduated summa cum laude with a BS in Mathematics and Education from The University of Scranton.
© Copyright 2023 alpha architect | All Rights Reserved | Home | Terms of Use | Privacy Policy | Disclosures | Subscribe | Contact Us